
▲이재길 교수. (사진제공=한국과학기술원)
한국과학기술원(KAIST)은 전산학부 이재길 교수 연구팀이 딥러닝 모델의 예측정확도와 훈련 속도가 대폭 향상된 새로운 모델 학습 기술을 개발했다고 20일 밝혔다.
딥러닝 모델을 학습하는 과정은 반복적으로 모델의 매개변수를 최적화하는 단계로 이뤄진다. 반복마다 훈련 데이터로부터 일부 데이터를 선정해 최적화에 사용하는데 이때 선정된 데이터 샘플을 배치(batch)라고 부른다. 무작위로 배치를 선택하면 최고의 정확도가 항상 보장되지 않기 때문에 이런 문제점을 개선하기 위해 최근 인공지능 학계에서는 더 나은 배치 선택 방법에 관한 연구가 활발히 진행되고 있다.
이 교수 연구팀이 개발한 기술은 딥러닝 모델의 학습 진행 상황에 맞게 최적의 배치를 구성하도록 하는 기술이다. 연구팀이 개발한 방법은 해당 데이터에 대한 이전 추론 결과를 활용한다.
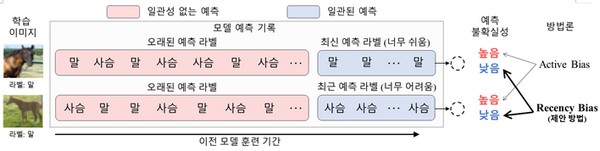
▲연구팀에서 개발한 ‘최신 편향(Recency Bias)’에서 불확실성을 계산하는 방식. (사진제공=한국과학기술원)
이재길 교수는 “이 기술이 텐서플로(TensorFlow) 혹은 파이토치(PyTorch)와 같은 기존의 심층 학습 라이브러리에 추가되면 기계 학습 및 심층 학습 학계에 큰 파급효과를 낼 수 있다”고 기대했다.
한편 이번 연구 결과는 데이터 처리 및 분석 분야의 국제 저명학술대회인 ‘국제컴퓨터학회 정보지식관리 콘퍼런스(ACM CIKM) 2020’에서 23일 발표된다. 연구팀에는 KAIST 지식서비스공학대학원에 재학 중인 송환준 박사과정 학생이 제1 저자로, 김민석 박사과정 학생과 김선동 박사가 각각 제2, 제3 저자로 각각 참여했다.
![잠자던 내 카드 포인트, ‘어카운트인포’로 쉽게 조회하고 현금화까지 [경제한줌]](https://img.etoday.co.kr/crop/140/88/2100528.jpg)
!['20년 째 공회전' 허울 뿐인 아시아 금융허브의 꿈 [외국 금융사 脫코리아]](https://img.etoday.co.kr/crop/140/88/2100022.jpg)
![[단독]"한 번 뗄 때마다 수 백만원 수령 가능" 가짜 용종 보험사기 기승](https://img.etoday.co.kr/crop/140/88/2100020.jpg)
![8만 달러 터치한 비트코인, 연내 '10만 달러'도 넘보나 [Bit코인]](https://img.etoday.co.kr/crop/140/88/2100256.jpg)

![환자복도 없던 우즈베크에 ‘한국식 병원’ 우뚝…“사람 살리는 병원” [르포]](https://img.etoday.co.kr/crop/140/88/2099863.jpg)
![불 꺼진 복도 따라 ‘16인실’ 입원병동…우즈베크 부하라 시립병원 [가보니]](https://img.etoday.co.kr/crop/140/88/2099872.jpg)
![“과립·멸균 생산, 독보적 노하우”...‘단백질 1등’ 만든 일동후디스 춘천공장 [르포]](https://img.etoday.co.kr/crop/140/88/2099348.jpg)












![잠자던 내 카드 포인트, ‘어카운트인포’로 쉽게 조회하고 현금화까지 [경제한줌]](https://img.etoday.co.kr/crop/300/170/2100528.jpg)
![윤석열 정부 전반기 국정성과, 여야 엇갈린 평가 [포토]](https://img.etoday.co.kr/crop/300/190/2100626.jpg)