한국은행은 16일 BOK 이슈 노트 '뉴스텍스트를 이용한 경기 예측: 경제 부문별 텍스트 지표의 작성과 활용' 보고서를 통해 "뉴스 텍스트 기반 경제지표는 비교 대상 공식 통계에 비해 0~9개월 선행하며, 공식 통계와 높은 상관관계를 갖는 것으로 나타났다"고 밝혔다.
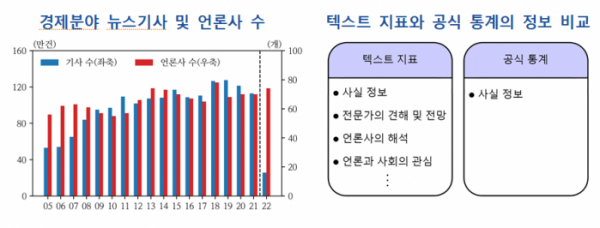
'코스피', '상승'과 같은 특정 단어를 포함하는 문장이 등장하는 기사를 추출하고 이들 기사가 전체에서 차지하는 비중을 계산한 뒤 생산, 물가, 고용, 주택가격 등 15개 부문의 경제지표로 작성한 결과다.
2005년 1월부터 올해 3월까지 인터넷에 게재된 경제 분야 뉴스 기사 전체를 분석했다. 연간 약 70개 언론사의 1000만 건 뉴스 기사, 문장 기준으로 연간 약 1800만 문장이다.
보고서에 따르면 이렇게 작성된 뉴스 텍스트 기반 경제지표를 기존 예측모형인 동적인자모형(DFM) 기반 선형모형에 추가하면 'GDP 전년동기대비 증가율 예측' 평균오차는 기존 0.743에서 0.681로 낮아졌다. 예측 정확도가 향상됐다는 뜻이다.
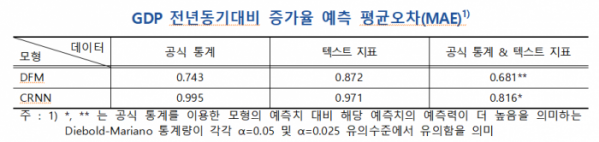
보고서를 작성한 한은 경제통계국 통계연구반 서범석 과장은 "텍스트 지표는 조사대상 기준일에 즉시 작성 가능해 주로 다음 달 중순 이후 발표되는 공식 통계보다 입수 시점이 빠르다"며 "전문가의 전망 등을 반영해 통계적으로 선행성을 갖기 때문에 GDP 예측력 향상에 기여한 것으로 판단된다"라고 말했다.
신종 코로나바이러스 감염증(코로나19) 영향이 컸던 2020년 6월 말을 살펴보면 텍스트 지표를 공식 통계에 추가한 경우 2020년 2분기 GDP 예측치가 실제에 더 근접하고, 경제 변수들의 변화를 더 잘 포착했다.
또 작성한 텍스트 지표 대부분은 공식 통계와 높은 상관관계를 보였다.
서 과장은 "기존 정량적 통계 모형만으로는 신속한 경기 예측이 어렵다. 보통 대상 시점과 공표 시점이 달라 한 달 이상 지연이 발생하기 때문"이라며 "그래서 최근 많은 연구가 뉴스텍스트 빅데이터의 중요성을 강조하고 있다"라고 밝혔다.
그러면서 "뉴스 텍스트는 다양한 전문가의 견해와 전망 등 정성적 정보를 포함하고 있고 실시간으로 입수할 수 있어서 이를 종합하고 정량화해 경기 예측에 활용할 필요가 있다"고 강조했다.
![어떤 주담대 상품 금리가 가장 낮을까? ‘금융상품 한눈에’로 손쉽게 확인하자 [경제한줌]](https://img.etoday.co.kr/crop/140/88/2101515.jpg)
![2025 수능 시험장 입실 전 체크리스트 [그래픽 스토리]](https://img.etoday.co.kr/crop/140/88/2101156.jpg)
!["최강야구 그 노래가 애니 OST?"…'어메이징 디지털 서커스'를 아시나요? [이슈크래커]](https://img.etoday.co.kr/crop/140/88/2101671.jpg)


















![[정치대학] 박성민 "尹대통령, 권위와 신뢰 잃었다"](https://img.etoday.co.kr/crop/300/170/2101600.jpg)
![예결위, 비경제부처 예산심사 첫날 [포토]](https://img.etoday.co.kr/crop/300/190/2101714.jpg)